
O crawl budget é o número de páginas que o Googlebot rastreia no seu site por ciclo, antes de gastar o limite. Segundo o Google Search Central (2024), sites com menos de 10.000 páginas raramente precisam se preocupar. O gargalo costuma ser TTFB acima de 600 ms, não o volume. Diagnostique antes de otimizar.
O crawl budget no WordPress define quantas das suas URLs o Google consegue visitar antes de pausar o rastreamento do site. Ele nasce de dois fatores: o limite de taxa que o servidor aguenta e a demanda que o Google tem pelo seu conteúdo. A gente vê no suporte da FULL, que gerencia mais de 150 mil sites, que o problema raramente é “o Google ignora meu site”; é o Googlebot gastando o orçamento em tag, autor e filtro de loja em vez das páginas de receita. Quem trata isso como questão técnica, e não de sorte, resolve. O conteúdos de SEO WordPress da FULL aprofunda cada camada deste diagnóstico.
O que é crawl budget: Definição operacional
O crawl budget é a soma de dois limites do Google: a taxa de rastreamento, que é quanto o seu servidor aguenta sem cair, e a demanda de rastreamento, que é o quanto o Google quer recrawlear suas URLs. Segundo o Google Search Central, abaixo de 10.000 páginas o assunto é secundário para a maioria dos sites.
Na prática, o desperdício de crawl budget aparece quando o Googlebot rastreia centenas de URLs sem valor de busca e deixa as páginas novas esperando dias na fila. O sintoma é sempre o mesmo: conteúdo de receita indexa devagar enquanto tag e filtro são visitados toda semana.
| Sinal de desperdício | Causa raiz no WordPress | Ação corretiva |
|---|---|---|
| URLs facetadas no índice | Filtros de WooCommerce indexáveis | Bloquear parâmetros no robots.txt |
| Tag e autor rastreados | Arquivos sem noindex no Rank Math | Marcar arquivos como noindex |
| Página nova demora a indexar | TTFB acima de 600 ms na hospedagem | Reduzir tempo de resposta do servidor |
O crawl budget não é um número que você configura: é uma consequência de quanto o servidor responde rápido e de quão limpo está o seu mapa de URLs.
Por que o Google não rastreia todas as suas páginas
O Googlebot abandona parte das URLs porque cada requisição custa recurso, e ele protege tanto a infraestrutura dele quanto o seu servidor. Quando o TTFB passa de 600 ms, o Google tende a reduzir a taxa de rastreamento para não derrubar o site, e o crawl budget efetivo encolhe.
Nos tickets da FULL, sites em hospedagem compartilhada lenta mostram esse padrão com frequência: o relatório de páginas indexadas trava e o “Descoberta, no momento sem indexação” cresce semana após semana.
O segundo motivo é demanda. Conteúdo que nunca muda perde prioridade de recrawl, enquanto URLs duplicadas (tag, busca interna, filtro) inflam a contagem e diluem o crawl budget em páginas que ninguém procura. O resultado é o Googlebot ocupado com ruído. Ferramentas como o Screaming Frog e o Google Search Console mostram exatamente onde o orçamento está vazando antes de qualquer ajuste.
Os 3 sinais de que seu crawl budget está sendo desperdiçado
Existem três sinais claros de crawl budget mal gasto, e todos aparecem no relatório de Páginas do Search Console em menos de cinco minutos. O primeiro é o número alto de URLs em “Descoberta, no momento sem indexação”, que indica o Google ciente das páginas mas sem orçamento para visitá-las. O segundo é o atraso de indexação: post publicado há mais de uma semana e ainda fora do índice.
O terceiro sinal é o mais comum em loja: parâmetros de URL no índice. Um WooCommerce com filtros de cor e tamanho indexáveis, sem bloqueio no robots.txt, gera milhares de URLs facetadas que consomem crawl budget sem valor de busca. Em uma loja acima de 1.000 produtos, o Googlebot tende a gastar a maior parte do orçamento nessas facetas. Marcar as facetas como noindex e bloquear os parâmetros no robots.txt libera o rastreamento para as páginas de produto reais. O guia de SEO técnico WordPress detalha esse mapeamento.
Como medir crawl budget no Search Console
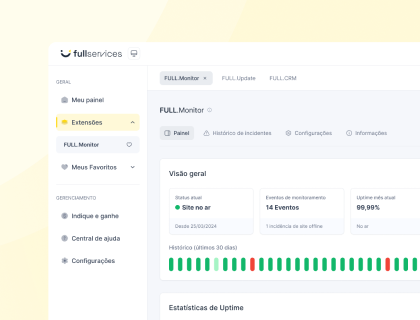
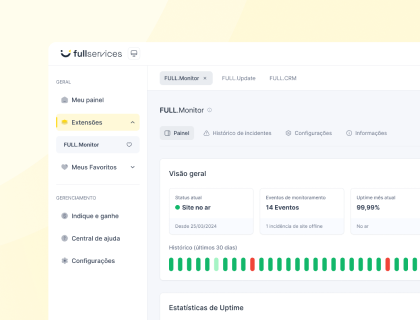
A medição do crawl budget começa nas Configurações do Google Search Console, na seção Estatísticas de rastreamento, que mostra o total de solicitações dos últimos 90 dias e o tempo médio de resposta. Um tempo de resposta médio abaixo de 200 ms é saudável; acima de 600 ms sinaliza que o servidor está limitando a taxa de rastreamento.
O gráfico de solicitações por dia revela se o Google estabilizou ou recuou no período recente.
O segundo passo cruza esse dado com o relatório de Páginas, onde o agrupamento por motivo (“Rastreada, mas não indexada”, “Descoberta, sem indexação”) aponta o vazamento. O sitemap XML entra como contraprova: se o Google reporta menos páginas válidas do que o seu sitemap do WordPress declara, há crawl budget preso em URLs erradas. O Rank Math e o Yoast SEO geram esse sitemap automaticamente.
Como otimizar o crawl budget no WordPress em 4 camadas
Otimizar crawl budget é cortar o que não deve ser rastreado antes de pedir mais rastreamento. A primeira camada é o robots.txt: bloquear parâmetros de filtro, busca interna e carrinho impede o Googlebot de gastar orçamento neles. A configuração de otimização do robots.txt resolve a maior fatia do desperdício na maioria dos cenários testados.
A segunda camada é a tag noindex via Rank Math em arquivos de tag, autor e data, que costumam responder por boa parte das URLs duplicadas de um WordPress padrão. A terceira é o controle de indexação por sitemap, declarando ao Google só o que tem valor de busca real. A quarta é a hospedagem: reduzir o TTFB devolve taxa de rastreamento direto, sem mexer em uma linha de configuração de SEO. Quando a indexação trava mesmo após a limpeza, o passo a passo de correção de indexação com Rank Math fecha o ciclo.
Crawl budget e Core Web Vitals: A conexão pelo servidor
Crawl budget e Core Web Vitals compartilham o mesmo gargalo na maioria dos casos: o tempo de resposta do servidor. Um TTFB alto piora o LCP que o usuário sente e, ao mesmo tempo, faz o Googlebot reduzir a taxa de rastreamento, então um servidor lento drena o crawl budget e o desempenho de uma vez só. Resolver a hospedagem tende a melhorar os dois indicadores juntos.
Por isso o diagnóstico de Core Web Vitals no WordPress antecede qualquer ajuste fino de rastreamento: não adianta declarar um sitemap perfeito se o servidor responde em 800 ms a cada requisição. O CrUX Dashboard do Google e o PageSpeed Insights medem o TTFB de campo, e é esse número, não a contagem de URLs, que costuma destravar o crawl budget em sites pequenos e médios. A ordem prática é clara: arrume o servidor primeiro, depois limpe o índice.
Quando vale investir em SEO técnico gerenciado
O controle de crawl budget mora dentro do SEO técnico, e ele é gerenciado, não hospedagem. A FULL inclui o Rank Math PRO no bundle: a partir do plano PRO, por R$849, você ativa o controle de noindex, sitemap e schema em um clique, o que dá cerca de R$85 por site quando o orçamento é dividido na carteira de projetos. Para uma agência que cuida de dezenas de WordPress, esse rateio é a diferença entre licenciar plugin a plugin e ter o stack de SEO técnico padronizado. Conheça os planos da FULL para ver o que entra em cada um.
Perguntas frequentes sobre crawl budget
O que é crawl budget no WordPress em termos práticos?
Crawl budget é o número de páginas que o Googlebot rastreia no seu site por ciclo antes de pausar. Ele combina a taxa que o servidor aguenta com a demanda que o Google tem pelo conteúdo. Em sites WordPress abaixo de 10.000 páginas, segundo o Google, ele raramente é o fator que limita a indexação.
Por que o Google não rastreia todas as páginas do meu site?
Porque cada rastreamento custa recurso e o Googlebot prioriza. Quando o TTFB passa de 600 ms, ele reduz a taxa para não sobrecarregar o servidor. E quando há muitas URLs duplicadas, como tag e filtro, o crawl budget se dilui em páginas sem valor de busca, deixando o conteúdo novo na fila.
É possível melhorar o crawl budget sem mexer no robots.txt?
Sim. A tag noindex via Rank Math em arquivos de tag, autor e data corta URLs duplicadas sem tocar no robots.txt. Reduzir o TTFB da hospedagem para abaixo de 200 ms também devolve taxa de rastreamento. O robots.txt acelera o resultado, mas o noindex e o servidor resolvem boa parte do problema sozinhos.
Qual a diferença entre crawl budget e indexação?
Crawl budget é quanto o Google rastreia; indexação é o que ele decide guardar no índice depois de rastrear. Uma página pode ser rastreada e não indexada por baixa qualidade. Sem crawl budget suficiente, porém, a página nem chega a ser avaliada, então o orçamento é o passo anterior à indexação.
Quantas páginas preciso ter para me preocupar com crawl budget?
O Google indica que sites abaixo de 10.000 páginas raramente precisam de gestão avançada de crawl budget. Acima de 10.000 URLs com conteúdo que muda rápido, ou em lojas WooCommerce com milhares de facetas, o assunto passa a importar. Antes desse volume, foco em TTFB e em limpar duplicatas resolve.
Próximos passos para liberar o rastreamento do seu site
Crawl budget no WordPress é gerenciável: comece medindo as Estatísticas de rastreamento no Search Console, identifique se o vazamento está nas URLs facetadas ou no TTFB da hospedagem, e ataque a maior fonte primeiro. Limpar tag e filtro com noindex e bloquear parâmetros no robots.txt costuma devolver o orçamento às páginas de receita em poucos ciclos. Para continuar aprendendo, o guia de SEO para WordPress da FULL reúne o método completo de SEO técnico em um só lugar.
Legenda: o relatório de Estatísticas de rastreamento revela onde o crawl budget está sendo gasto antes de qualquer ajuste.