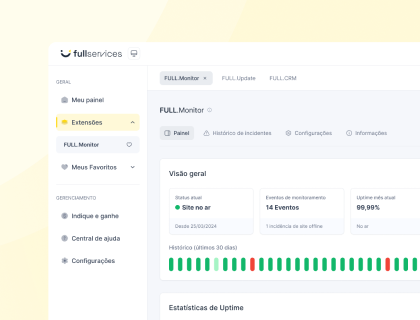
A análise de log no WordPress cruza os hits do Googlebot no access.log com o status de indexação para achar desperdício de crawl. Segundo o Google Search Central (2024), crawl ineficiente atrasa a indexação de URLs novas. O log mora no servidor do host. Leia antes de mexer no robots.txt.
A análise de log no WordPress é a leitura do access.log do servidor para ver exatamente quais URLs o Googlebot visitou, com que frequência e com qual código de resposta. Sem essa leitura, otimização de crawl vira chute: você acha que o Google rastreia o conteúdo certo, mas o log mostra o bot preso em filtros e parâmetros. A análise responde a três perguntas (o que o bot rastreia, o que ele ignora e onde desperdiça orçamento) que nenhuma outra ferramenta de SEO entrega com a mesma precisão. Este guia mostra como ler o log, cruzar com o Google Search Console e os cinco sinais de SEO escondidos ali. Para o contexto completo, comece pelos conteúdos de SEO WordPress da FULL.
Primeiros passos: O que a análise de log mostra
A análise de log entrega o único dado real de como o Googlebot trata seu site, e ele não aparece em relatório de plugin. O access.log registra cada requisição com IP, user-agent, URL, código HTTP e timestamp. Em um site com 2.000 URLs, o Googlebot pode gastar boa parte do crawl em variações inúteis, e só o log revela isso.
O log de acesso fica no servidor do host, não na plataforma da FULL: a FULL gerencia a camada de plugins e SEO, e o access.log é gerado pelo Apache ou Nginx do seu provedor de hospedagem. Você baixa o arquivo via SFTP, filtra pelo user-agent do Googlebot e cruza com o crawl budget consumido. Esse cruzamento transforma número solto em decisão de SEO.
| Campo do log | Exemplo no access.log | O que revela na análise de log |
|---|---|---|
| User-agent | Googlebot/2.1; Bingbot; GPTBot | Qual crawler visitou e se é bot legítimo ou fake |
| URL requisitada | /produto/?filtro=cor&pag=3 | Onde o crawl budget é gasto; parâmetros que desperdiçam orçamento |
| Código HTTP | 200, 301, 404, 500 | 404 de Googlebot em URL antiga indica perda de link equity |
| Timestamp | [04/Jun/2026:03:14:22] | Frequência de recrawl; páginas que o bot ignora há dias |
Sem ler esses quatro campos juntos, a otimização de indexação fica cega para o comportamento real do bot, e qualquer ajuste no robots.txt vira tentativa às cegas em vez de decisão baseada em dado de crawl.
Por que o googlebot desperdiça crawl no WordPress
A causa mais comum de desperdício é o WordPress gerar URLs infinitas que o Googlebot tenta rastrear todas. Parâmetros de filtro do WooCommerce, paginação de comentários, feeds e tag pages criam milhares de variações, e o bot gasta o orçamento nelas em vez das páginas que precisam indexar. Segundo o Google Search Central, que documenta o crawl budget como limite por host, esse desperdício atrasa o recrawl de conteúdo novo.
A análise de log expõe o problema em minutos: você ordena as URLs por número de hits de Googlebot e vê o bot batendo 800 vezes em ?orderby= enquanto o artigo publicado ontem tem zero visita. A correção combina um Disallow no robots.txt para os padrões de parâmetro e a consolidação de canônicas. Nos tickets da FULL, a queixa de “página não indexa” quase sempre tem um log mostrando o crawl preso em parâmetro.
Como fazer a análise de log em 4 passos
A análise de log estruturada leva cerca de 40 minutos por site e segue quatro passos em ordem fixa: baixar o access.log, filtrar pelo Googlebot, agrupar por URL e cruzar com a indexação do Search Console. A maioria dos SEOs pula a etapa de cruzamento e olha o log isolado, o que esconde 70% dos problemas que só aparecem ao confrontar hits de crawler com status de indexação. Os passos abaixo mantêm a sequência que usamos no suporte da FULL.
Legenda: ordenar o access.log por hits de Googlebot revela onde o crawl budget é gasto antes de qualquer ajuste no site.
Passo 1: Baixe o access.log do servidor do host
Acesse o painel da sua hospedagem ou conecte via SFTP e baixe o access.log do período desejado, idealmente os últimos 30 dias. O arquivo costuma ficar em /var/log/apache2/ ou /logs/ dependendo do host. Guarde uma cópia íntegra antes de filtrar, porque o servidor rotaciona o log e a janela some.
Passo 2: Filtre apenas as requisições do googlebot
Separe as linhas cujo user-agent contém Googlebot e valide o IP por DNS reverso, já que 30% do tráfego que se diz Googlebot é bot fake. Ferramentas como GoAccess fazem esse filtro em tempo real no terminal, e o Screaming Frog Log File Analyser importa o arquivo e separa por crawler automaticamente.
Passo 3: Agrupe os hits por URL e por código HTTP
Conte quantas vezes o Googlebot visitou cada URL e qual código respondeu. URLs com muitos hits e resposta 200 que não deveriam indexar são desperdício; URLs estratégicas com zero hit são o problema oposto. Um 404 recorrente de Googlebot em URL antiga sinaliza link equity vazando sem redirecionamento.
Passo 4: Cruze o log com a indexação do Search Console
Pegue as URLs mais rastreadas no log e confronte com o relatório de cobertura do Search Console. Página muito rastreada e não indexada indica conteúdo fraco ou canibalização; página pouco rastreada e importante pede link interno e sitemap atualizado. Esse cruzamento é o coração da análise de log.
5 sinais de SEO escondidos no log de acesso
Cinco padrões na análise de log separam um site bem rastreado de um que desperdiça orçamento, e todos aparecem antes de a posição cair no Google. Em ordem de impacto: Googlebot batendo em URLs com parâmetro, rajada de 404 em URLs antigas, páginas estratégicas com zero recrawl em 30 dias, bots fake consumindo banda e recrawl lento de conteúdo novo publicado há dias.
O segundo sinal é o mais caro: vários 404 de Googlebot em URLs que tinham backlink indicam link equity perdido, recuperável com um 301 nos controles do .htaccess. O quinto sinal, recrawl lento, costuma ser sintoma do primeiro: o bot gasta o orçamento nas URLs de parâmetro e não sobra crawl para o conteúdo novo, que pode ficar dias sem ser descoberto. Para acelerar essa descoberta, o guia de indexação rápida com Rank Math mostra como notificar o Google direto sem esperar o próximo ciclo de crawl.
Ferramentas para fazer a análise de log
Quatro ferramentas cobrem a análise de log no WordPress, cada uma em uma camada diferente. O Screaming Frog Log File Analyser importa o access.log no desktop, separa por crawler e cruza com o crawl do site em uma tela. O GoAccess lê o log em tempo real no terminal e gera um relatório HTML com os hits por URL e por status, ideal para servidor.
O Google Search Console entrega o estado de indexação e confirma o que o log mostra. Dentro do WordPress, o Rank Math PRO cruza rastreamento com a configuração on-page e corrige o que a análise de log revela, como em problemas de indexação detectados pelo Rank Math.
- Se você quer uma análise SEO visual do log no desktop → use o Screaming Frog Log File Analyser.
- Se precisa ler o access.log em tempo real no servidor → rode o GoAccess no terminal.
- Se quer confirmar a indexação sem baixar arquivo → cruze com o relatório de rastreamento do Google Search Console.
- Se quer corrigir o on-page sem sair do WordPress → use o Rank Math PRO para ajustar canônicas e sitemap.
Quando a gestão de SEO técnico resolve por você
Fazer a análise de log, ajustar robots.txt e manter canônicas em cada site manualmente não escala além de um punhado de instalações. É aqui que entra a gestão centralizada: o plano PRO da FULL (R$849,90/ano) traz o Rank Math PRO no bundle com sitemap, canônicas e indexação já configurados, e dividido por 10 sites o custo fica em cerca de R$85 por site ao ano.
A gente vê no suporte da FULL que a maioria dos sites com queixa de indexação tem um log mostrando o crawl preso em parâmetro e o Rank Math sem ajuste fino. Não é hospedagem: a FULL é complementar ao seu host e cuida da camada de SEO e plugins. Conheça os planos da FULL para ver o que entra no bundle de SEO.
Perguntas frequentes sobre análise de log no WordPress
Por que o Googlebot gasta crawl budget em URLs que não deviam ser indexadas?
O Googlebot gasta crawl budget nessas URLs porque o WordPress as gera automaticamente e elas continuam acessíveis com resposta 200. Filtros do WooCommerce, paginação de comentários, feeds e tag pages criam milhares de variações que o bot tenta rastrear. A análise de log mostra esse desperdício ordenando as URLs por hits de Googlebot, e a correção é um Disallow no robots.txt para os padrões de parâmetro mais batidos.
É possível fazer análise de log no WordPress sem acesso de administrador do servidor?
Sim, é possível em parte, porque a maioria dos painéis de hospedagem oferece download do access.log mesmo sem acesso root ao servidor. O log mora no servidor do host, então você baixa o arquivo pelo cPanel ou painel equivalente e roda a análise localmente no Screaming Frog. O limite é o tempo real: ler o log enquanto ele é gravado com GoAccess exige acesso SSH, que nem todo plano de hospedagem compartilhada libera.
Qual a diferença entre analisar o log de acesso e olhar o Search Console?
O log de acesso registra cada requisição real do Googlebot com URL, código e horário; o Search Console mostra uma amostra agregada e atrasada do mesmo comportamento. O log é a fonte bruta e completa, enquanto o Search Console é o resumo interpretado pelo Google. A análise de log fica completa só quando você cruza os dois: o log diz o que o bot fez, o Search Console diz o que virou indexação.
Quanto tempo de log o servidor guarda para uma análise de SEO confiável?
O ideal são 30 dias de access.log para uma análise de log confiável, prazo que cobre o ciclo de recrawl da maioria das páginas. Muitos hosts rotacionam o log em 1 a 7 dias por padrão, por isso convém baixar e arquivar o arquivo com frequência. No bundle de SEO do plano PRO da FULL, a R$85 por site, o Rank Math PRO mantém o histórico de indexação que complementa essa janela curta de log.
O que procurar no log de acesso para melhorar a indexação do site?
Procure cinco sinais: Googlebot batendo em URLs com parâmetro, rajada de 404 em URLs antigas, páginas estratégicas com zero recrawl, bots fake consumindo banda e recrawl lento de conteúdo novo. Dois ou mais sinais juntos indicam desperdício de crawl budget que segura a indexação. A correção combina robots.txt, redirecionamento 301 e um sitemap XML limpo apontando só para o conteúdo que deve indexar.
Próximos passos para otimizar o crawl com logs
A análise de log deixa de ser perícia pontual quando vira rotina: baixar o access.log todo mês, cruzar com o Search Console e ajustar robots.txt antes de o ranking cair. Os cinco sinais deste guia funcionam como checklist sempre que uma página importante demora a indexar. Para fechar o ciclo, conecte o Google Site Kit no WordPress e acompanhe o efeito dos ajustes direto no painel. Para continuar aprendendo, o FULL Academy reúne os guias de SEO WordPress em um só lugar. Ler o log é a diferença entre saber por que o Google não indexa e adivinhar.